I built an agent-driven development pipeline in Unity using Claude Code. The goal was ambitious: have AI replicate my entire workflow, from reading a game design document to shipping playable iterations, with minimal human involvement.
It worked, but not the way I had hoped. This article is about what I built, why it fell short, and what I think that means for AI-driven development.
How I Got Here
I've been using LLMs for development since ChatGPT 3.5 launched in late 2022. At first it was just copy-pasting from a chat interface: isolating problems I could explain in a few prompts, manually porting solutions back into my code, and simple autofill with Copilot. It was useful but limited. A better Stack Overflow. Less boilerplate to write.
When I moved to agentic tools like Cursor in mid 2025, the experience was smoother for small projects (vibe coding a portfolio site or an iOS app worked well enough when I didn't care how the internals looked). But on a larger Unity codebase (~30k lines with real complexity and technical debt), the results were inconsistent and buggy. The agent couldn't grasp the full picture.
Still, a question kept nagging me: what if I'm just not using this properly? Every time I sat down to write code I already knew how to implement, I couldn't shake the feeling that an agent could do it a thousand times faster, if only it had the right context and instructions. The tedious parts of development felt like they should be automatable. And the interesting parts (the ambiguous decisions, the architectural tradeoffs) are what I enjoy more spending my time on.
So I decided to properly investigate. I picked up Claude Code and set out to build a pipeline that would... replace me.
Three Approaches to Agentic Development
Before diving in, it's worth laying out the spectrum of how developers use AI agents:
- Vibe coding: No architecture or context management. The agent does most of the work; the developer only specifies desired output. A CLAUDE.md file and basic memory might help, but the agent is largely on its own.
- Agent-assisted: The developer drives. You might ask the agent to implement a specific method, or hand it a well-scoped task with plenty of context. The agent accumulates some knowledge over time, but it's not responsible for complex multi-system changes without heavy developer involvement.
- Agent-driven: The agent replicates your entire workflow. It knows the vision, the architecture, the conventions, the task list. It has a context system for navigating the codebase. You monitor and course-correct, but the agent makes the decisions.
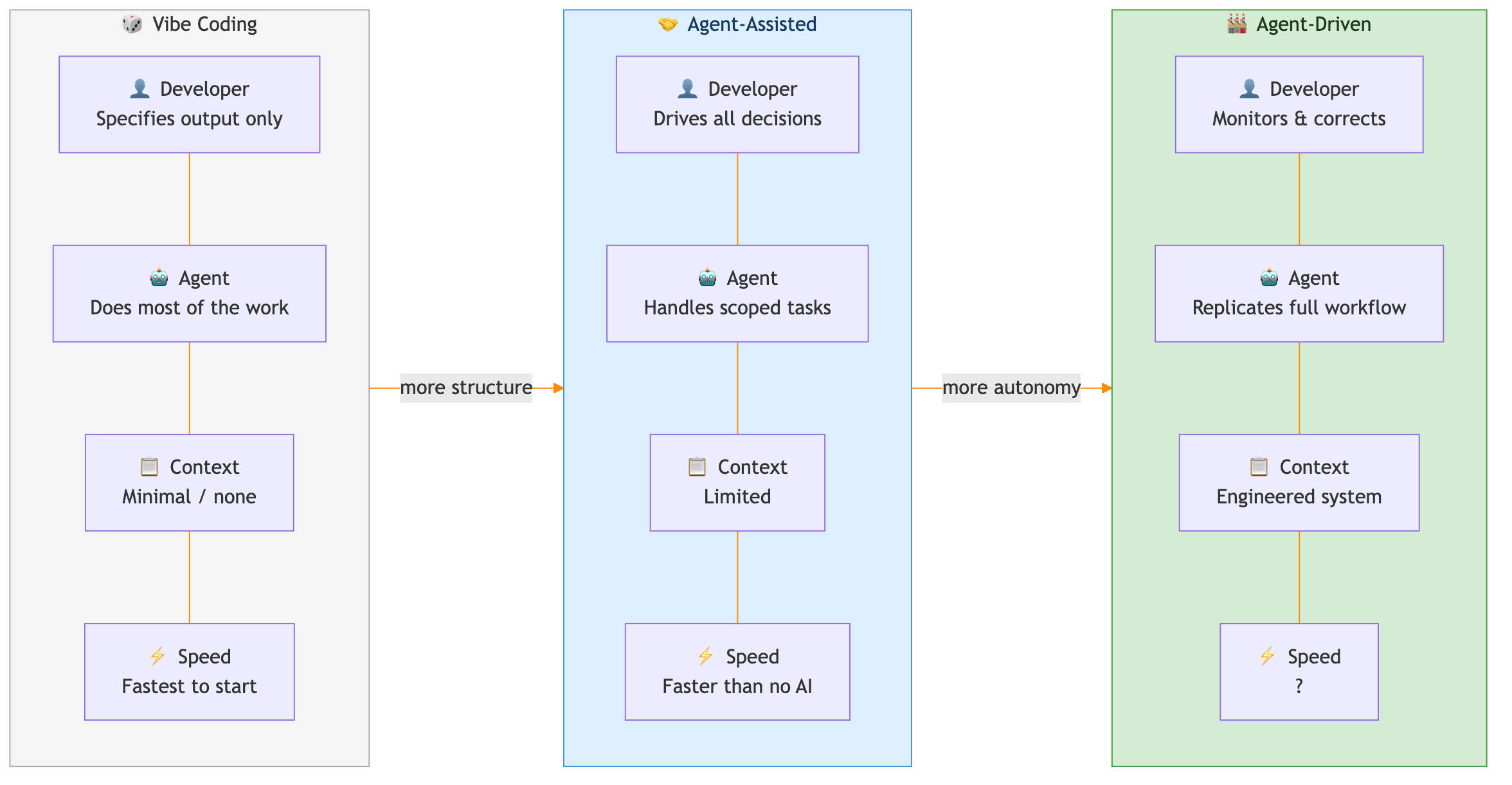
I wanted to go all in. The goal was agent-driven: build a system that knows everything I know, makes decisions like I would, and keeps working until the project is done.
Pipeline Design
You can find all final Claude Code configurations here.
Skills
First, I encoded my domain knowledge into Claude Code skills:
- Coding conventions
- Dependency injection patterns
- Folder organization and naming
- Performance, architecture, and testing best practices
The Pipeline
I scoped it as small as possible: simple hyper-casual games in Unity. Games so simple you could vibe code them. But I wasn't optimizing for the easiest path. I wanted a pipeline that could scale. Since these games are code-only, most of what I found applies to many software pipelines, not just game dev.
- Developer provides a game design document and technical requirements.
- An orchestrating agent asks clarifying questions, identifying gaps in the spec.
- The orchestrator scaffolds a new Unity project (correct settings, packages, MCP tooling, folder structure) all documented in an Architecture.md.
- An iteration system breaks the game into meaningfully playable milestones.
- The orchestrator decomposes each iteration into tasks, then subtasks.
- For each subtask:
- A subagent collects relevant context
- The agent prepares a development plan
- It implements, writes tests, compiles, and runs them
- The developer verifies in-game behavior where applicable
- The agent updates the context system, architecture docs, game design document, and iteration progress
- It commits and pushes

The Context System
Possibly the biggest challenge is context engineering; how does the agent find what it needs from the current state of the project?
Dumping the entire codebase into the context window is a bad idea for bigger projects, as the context window has a limited size and gets more expensive and less reliable the more you fill it up. Claude Code's built-in Explore agent consumes a lot of tokens searching and still misses things, especially in Unity, where critical information lives in prefabs, scenes, and scriptable objects that are not designed to be used outside of Unity.
I considered RAG and graph databases, but settled on a hierarchical tree-based system that mirrors the architecture:
- Every script starts with a
//@contextblock (a 10-line summary of what it does). - Every folder contains a
_contextfile describing its assets and associated subsystems. - Some non-script assets have a companion
.context.yamlwith additional metadata. - Some scene GameObjects carry a
ContextInfoMonoBehaviour describing their role, paired with a custom MCP for collecting scene context. - An Architecture.md ties it all together (a map of how subsystems connect, serving as the entry point for the subagent's context search).
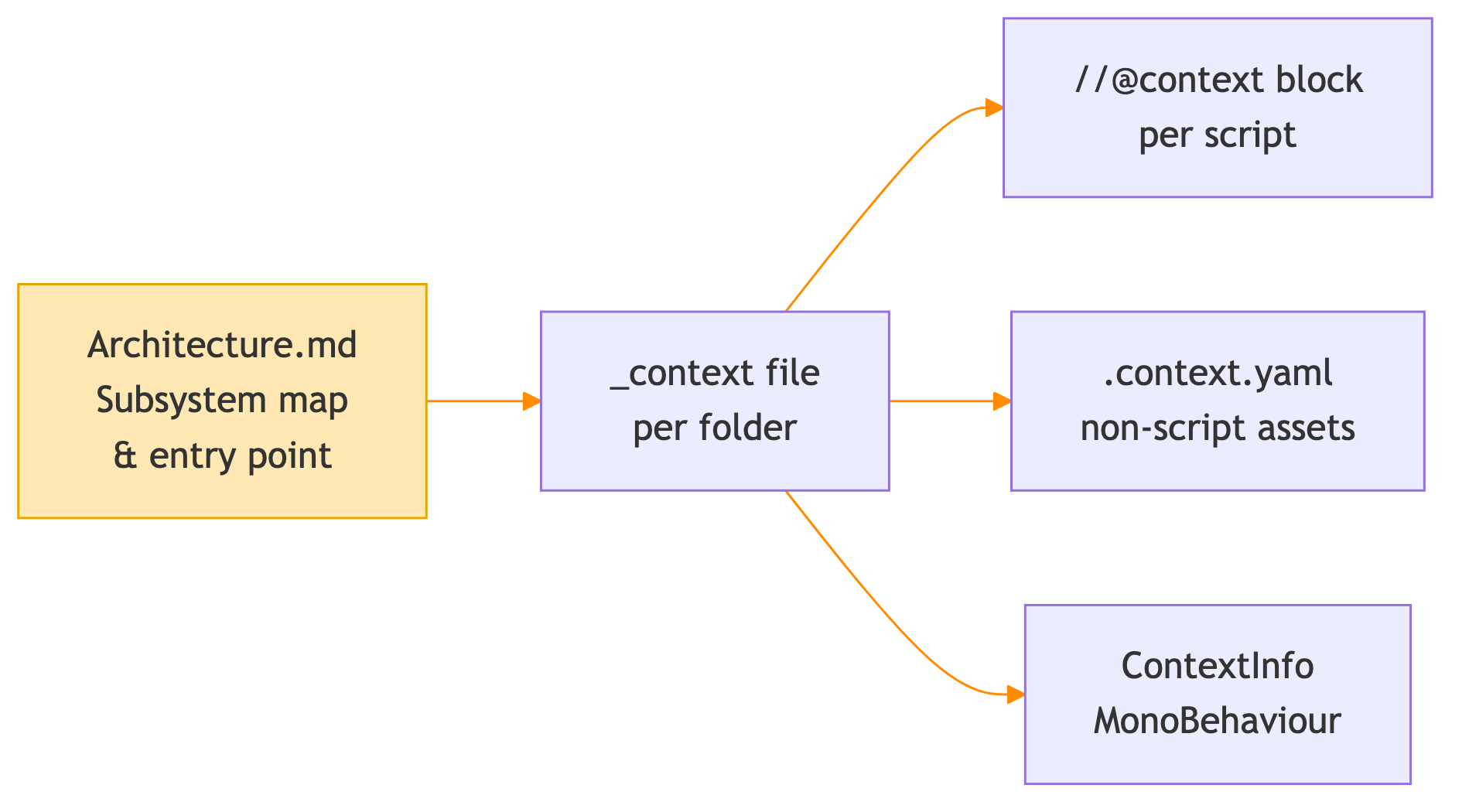
The pipeline keeps all of this up to date after every change.
MCP
For Unity integration, I used Ivan Muzak's Unity MCP. Its reflection API allows the agent to write a script batching multiple actions, which I review, and then execute inside Unity without waiting for recompilation. I also wrote an MCP skill to teach the agent optimal usage patterns.
Putting It Together
With all the pieces in place:
- Scaffolding for project setup
- A context system tracking everything
- MCP for Unity interaction
- An iteration system for planning
- A development flow for execution
- Conventions for code quality
Plus some extras: task revision and backtracking, a simple backlog, and reconciliation of any manual work back into the pipeline.
This sort of simulates how the development process works in my head.
I ran the pipeline four times on the same game idea, starting from scratch each time, identifying issues, and improving the pipeline between runs. I built a self-modifying skill that let an agent propose pipeline changes, though I had to double-check everything it suggested for reasons I'll get into now.
The Game
I created a hyper-casual game where you have to slice lines in certain ratios showing up in a Rhythm. You can see a short video of the game here.
Did the Pipeline Work?
Yes, but not in a sustainable way.
I had high hopes, especially since I was only trying to make simple hyper-casual games.
The pipeline is simple, far simpler than what you'd need for a proper game. It's designed for one developer making code-only hyper-casual games. And yet, it includes enough moving parts (development steps, iteration tracking, conventions, context maintenance) that things break down. Here's where and why.
It's Expensive, and Probably Getting More Expensive
Claude Code offers three model tiers. For this pipeline, only Opus performed consistently enough. Sonnet would forget instructions; when confronted, it would just apologize. Opus did this far less often. It's the first model I've used that I could trust over longer sessions.
I optimized where I could (subagents for context retrieval run on Sonnet), but roughly 80% of the pipeline needed Opus.
The problem: at $5/M input tokens and $25/M output tokens for a 200K context window that fills up fast, costs add up quickly. Four or five subtasks already force a session compaction or restart. The most affordable path is a Pro or Max subscription ($20/$100/$200 per month) with hourly and weekly limits, but Opus burns through those budgets fast, especially on tasks that touch many files.
Even though in the past few years LLM providers have proved they can create cheaper and better models, I'm not sure that trend will continue. I think it's a strategy: sell AI cheaper than it costs, get it deeply integrated into customer workflows, and then slowly raise prices to reflect the real cost. The prices may go down as models get more efficient, or they may go up once the market is locked in.
The Best Model Still Isn't Good Enough
Even in this simple pipeline, there's a surprising amount of state the agent needs to track. Every detail matters and can snowball if missed.
Opus is significantly better than Sonnet here. It follows pipeline steps consistently. But it still forgets: context from earlier in the session, coding conventions, even things stated in a fresh prompt. The gap between "impressively capable" and "reliably autonomous" is wider than it feels.
The Context Window Is a Black Box
I have no visibility into how Claude Code composes its context. Which parts of my messages are retained? Are thinking traces included? How are skills loaded? The 200K window fills up faster than expected, and I can't tell whether that's inherent or a lack of optimization in how tokens are managed behind the scenes.
I doubt this is intentional, but their priority is clearly shipping new features as fast as possible rather than optimizing how their agentic solution handles tokens. I end up paying extra for that lack of optimization. More transparency and control here would go a long way.
Sessions Start Fresh. Always.
LLMs know a lot, arguably too much. But in software development, there usually isn't one right answer. Solutions are domain-specific, opinionated, shaped by experience.
Every new session is like onboarding a brilliant employee with amnesia. Fast, knowledgeable, but starting from zero every time. I hand it the same instructions, the same context, and hope it performs as well as last time. This is why context engineering matters so much, and why it's so hard to get right.
I also can't trust the agent to "learn" on its own. If it stores something in its context without careful guidance, it can poison every other carefully crafted prompt.
Prompt Engineering Is a Moving Target
There's a narrow band between too vague and too specific:
- Over-specify, and you bloat the context with things the model could figure out itself.
- Under-specify, and it fills in the blanks with something completely unexpected.
- Be too rigid ("always write tests"), and it writes useless tests that never fail.
- Generic instructions like "be concise" or "write clean code" have no measurable effect.
I couldn't get this right upfront. I had to iterate by running the agent, evaluating results, and tuning, which is its own ongoing cost.
It Can't Think Outside the Box
As an engineer, when I'm solving a problem, I regularly question whether I'm even looking at it the right way. I get a hunch that maybe the whole approach is off. That instinct is how I catch bad decisions early.
LLMs do the opposite. They affirm my direction and keep digging. If I'm headed the wrong way, the agent will enthusiastically help me get there faster. To be fair, Opus occasionally pushes back or suggests a different approach, but far more often it validates whatever you say and doubles down.
Agent-Driven Means All-In
The pipeline's context system only works if it's up to date. Any work I do outside the pipeline (a quick manual fix, a tweak in the Unity editor) creates a gap between reality and what the agent knows. That gap degrades every subsequent decision.
You Lose Ownership of Your Code
Development goes faster because the agent writes everything. That's fine until a "fix it" prompt doesn't fix the issue, and I have to dive into code I've never read. I started wondering: should I review everything it writes? At what depth? Would it be faster to write most of the code myself and use AI only as an assistant?
There's an uncomfortable tension between speed and understanding.
Are You Willing to Invest in a Lot of Tokens?
To summarize the problems:
- You need the best models, and they're expensive.
- They're still not reliable enough for autonomous work.
- They degrade as context grows.
- Context engineering may not be a solvable problem.
- Prompt optimization is continuous and never "done."
- You end up responsible for code you didn't write and may not understand.
And the most tricky part:
A suboptimal agentic pipeline is like a brute-force algorithm. You can throw more computation at it to compensate for its shortcomings, but it will never scale.
Meaning, you can make agent-driven development work if you're willing to invest enough:
- Pay for tokens and trust that it will be profitable long term.
- Spend more tokens on more agents double-checking that everything was followed properly. Triple-check, quadruple-check, your bank account is the limit.
- Hire a large number of specialists for an extended period to engineer a carefully crafted pipeline dedicated to your specific problem domain, then lay them off for more token headroom.
- Brute-test the entire pipeline. When there are issues, throw more agents at it.
And all of that effort produces a pipeline for one very specific type of product.
I haven't spent tens of thousands of dollars on a large-scale experiment, but my observations tell me that transformer-based models, as they work today, are not going to replace software engineers.
Maybe I'm wrong. Maybe someone has already cracked the context problem, built the perfect pipeline, and achieved full automation across a wide range of software products. I doubt it. If software were "solvable" by pattern matching over training data, we would have found that solution long before LLMs came along. These models lack understanding, memory, and creativity in any meaningful sense. They apply patterns recognized in training data to new patterns. I find it hard to believe that the solution to "software", which by extension could be the solution to a lot of things, was already there in the data and we just needed LLMs to extract it for us.
I'm not claiming LLMs are useless. They're possibly the most impressive development tool I've ever used. I'll be writing about agent-assisted approaches (where I think the real value is) in a follow-up article.
Please subscribe to my newsletter to get notified once it is out!

Member discussion: